Meta MMM Robyn Walkthrough 04 - 로빈 실행과 결과 해석
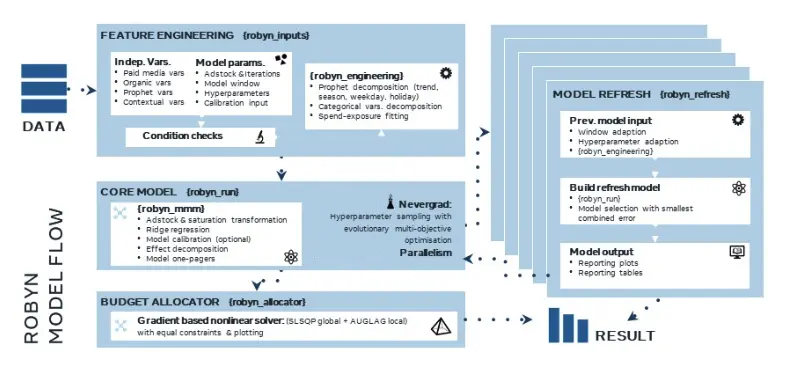
지난 과정을 잘 따라 오셨다면 로빈이 모델링을 돌리기 직전까지 와있는 것입니다. 이제 처음으로 모델링을 해보고 어떤 결과가 나오는지를 같이 확인해 보겠습니다.
Robyn - Step 3: 초기 모델 만들기
지금 우리가 어디에 있는지 확인하고 진행해보죠. 계속 참고하고 있는 demo.R 파일에서 Step 3: Build initial model 부분을 이제 시작하고 있습니다.
Trials and Iterations - 모델 학습
지금까지 우리가 해 온것은 모델에게 먹일 데이터를 준비하고, 모델이 이 데이터에서 무엇을 얼마나 참고하면 될지를 정해준 것이라고 보면 됩니다. 이제 robyn_run() 함수에 이것들을 넣어서 돌릴 것입니다. Meta는 이 과정을 trials and iterations 라고 표현하는데요, 실질적으로는 머신 러닝이 데이터로부터 반복 학습하는 과정이 이루어지는 부분입니다. 가이드대로 아래 코드를 복사해서 실행해보죠.
OutputModels <- robyn_run(
InputCollect = InputCollect, # feed in all model specification
cores = NULL, # NULL defaults to (max available - 1)
iterations = 2000, # 2000 recommended for the dummy dataset with no calibration
trials = 5, # 5 recommended for the dummy dataset
ts_validation = TRUE, # 3-way-split time series for NRMSE validation.
add_penalty_factor = FALSE # Experimental feature. Use with caution.
)콘솔에서 이런 결과를 볼 수 있다면 성공입니다.
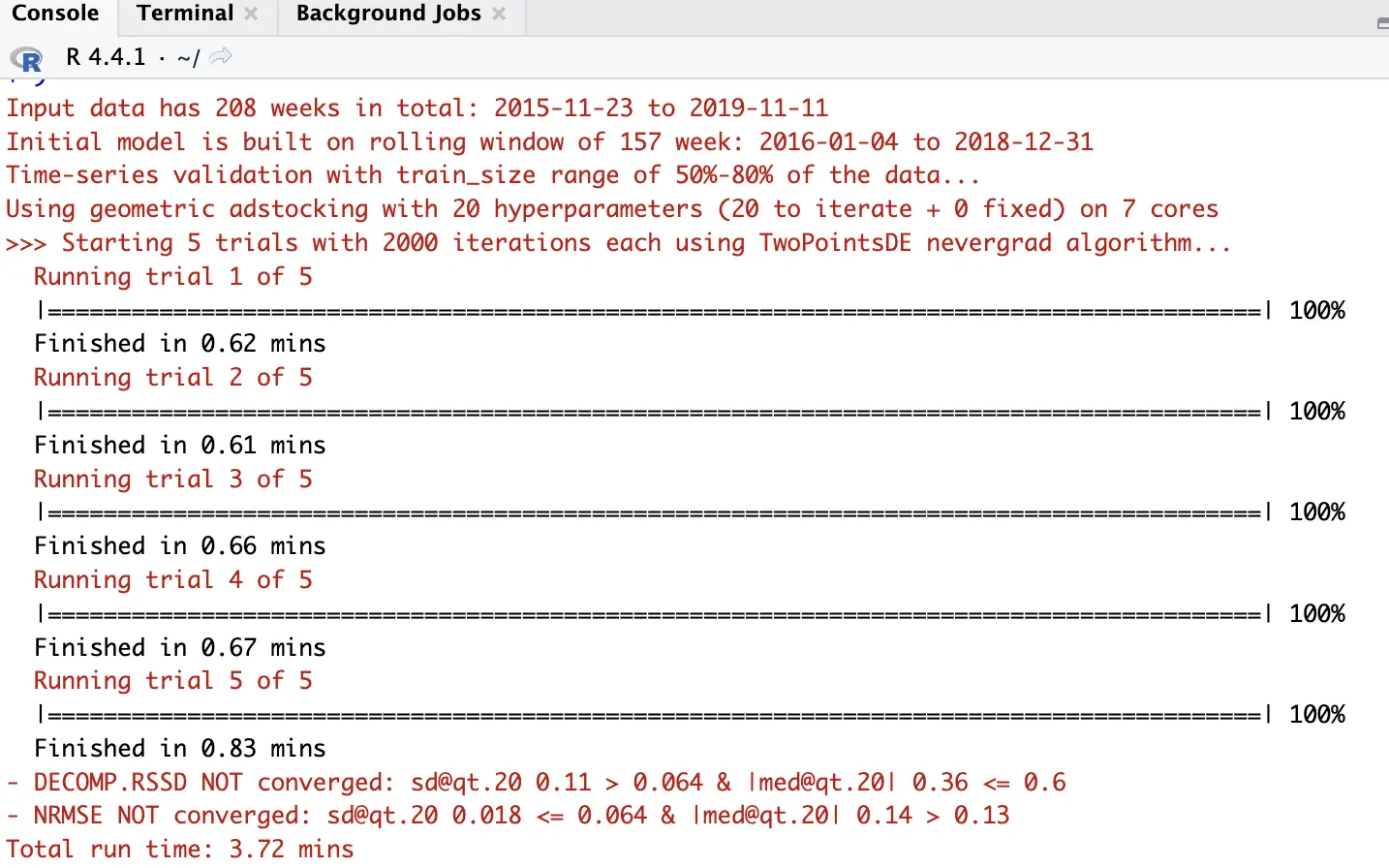
Macbook Air M3 기준 4분 미만으로 데모 데이터셋 학습이 끝납니다. 어떤 데이터로 모델 만들고 학습 데이터 비율이 어느 정도고 adstock 구하는 함수가 뭐고 등등 주요 사항들이 나오네요. 다음 코드를 실행해 봅시다.
print(OutputModels)OutputModels 객체를 출력을 해보는 것인데요, 구체적인 속성들이 아래와 같이 표시됩니다.
Total trials: 5
Iterations per trial: 2000 (2002 real)
Runtime (minutes): 3.72
Cores: 7
Updated Hyper-parameters:
facebook_S_alphas: [0.5, 3]
facebook_S_gammas: [0.3, 1]
facebook_S_thetas: [0, 0.3]
newsletter_alphas: [0.5, 3]
newsletter_gammas: [0.3, 1]
newsletter_thetas: [0.1, 0.4]
ooh_S_alphas: [0.5, 3]
ooh_S_gammas: [0.3, 1]
ooh_S_thetas: [0.1, 0.4]
print_S_alphas: [0.5, 3]
print_S_gammas: [0.3, 1]
print_S_thetas: [0.1, 0.4]
search_S_alphas: [0.5, 3]
search_S_gammas: [0.3, 1]
search_S_thetas: [0, 0.3]
tv_S_alphas: [0.5, 3]
tv_S_gammas: [0.3, 1]
tv_S_thetas: [0.3, 0.8]
lambda: [0, 1]
train_size: [0.5, 0.8]
Nevergrad Algo: TwoPointsDE
Intercept: TRUE
Intercept sign: non_negative
Time-series validation: TRUE
Penalty factor: FALSE
Refresh: FALSE
Convergence on last quantile (iters 1902:2002):
DECOMP.RSSD NOT converged: sd@qt.20 0.11 > 0.064 & |med@qt.20| 0.36 <= 0.6
NRMSE NOT converged: sd@qt.20 0.018 <= 0.064 & |med@qt.20| 0.14 > 0.13주목할 것은 모델이, 정확하게는 Nevergrad가 TwoPointsDE 를 옵티마이저(optimizer)로 알아서 선택했다는 점입니다. 주어진 상황에서 머신 러닝이 최선의 결과를 도출하기 위한 방법이 옵티마이저이고, 각 옵티마이저마다 특징이 다르기에 결과도 달라집니다. Nevergrad는 아래 사항들을 고려해서 옵티마이저를 자동으로 선택한다고 하네요.
- 파라미터의 개수
- 작업의 병렬처리 개수, 즉
num_workers - 변수의 유형, 연속형이냐 분류형이냐 등등
- 데이터 노이즈의 정도
옵티마이저 종류가 많은데요, 여기에서 목록을 확인할 수 있으니 관심이 있으신 분들은 참고해보세요.
Check Plots - 학습 결과 검증을 위한 그래프 출력과 해석
robyn_run() 호출 이후엔 이 모델이 얼마나 학습이 잘 되었는지, 원하는 결과에 잘 수렴했는지를 그래프(plot)으로 확인해볼 수 있습니다. 아래 코드를 실행해 볼까요?
OutputModels$convergence$moo_distrb_plot제 경우엔 이렇습니다. 이 그래프를 어떻게 해석해야 하는지 난감했는데요, 어찌어찌 배워낸 내용을 남깁니다.
DECOMP.RSSD
Decomposition Root Sum of Squared Differences의 약자입니다. 머신 러닝 학습 과정에 사용되는 각 변수에는 가중치(W, weight)가 붙는데요, 이 가중치가 과도하게 왜곡되지 않도록 제약을 주는 역할을 합니다. 결과적으로 모델이 지나치게 특정 변수에 의존하는 것을 방지하게 되고, 일반적으로 수치가 작을수록 모델이 더 균형 잡힌 가중치를 부여하고 있음을 나타냅니다.
NRMSE
Normalized Root Mean Squared Error의 약자로 모델의 예측값과 실제값 사이의 차이를 측정하는 지표입니다. 이에 따라 NRMSE는 모델의 예측 정확도를 나타낸다고 볼 수 있고, 값이 작을수록 예측이 실제 데이터와 더 가깝다는 것을 의미합니다.
이제 이런 정의를 유념하면서 그래프를 해석해보죠.
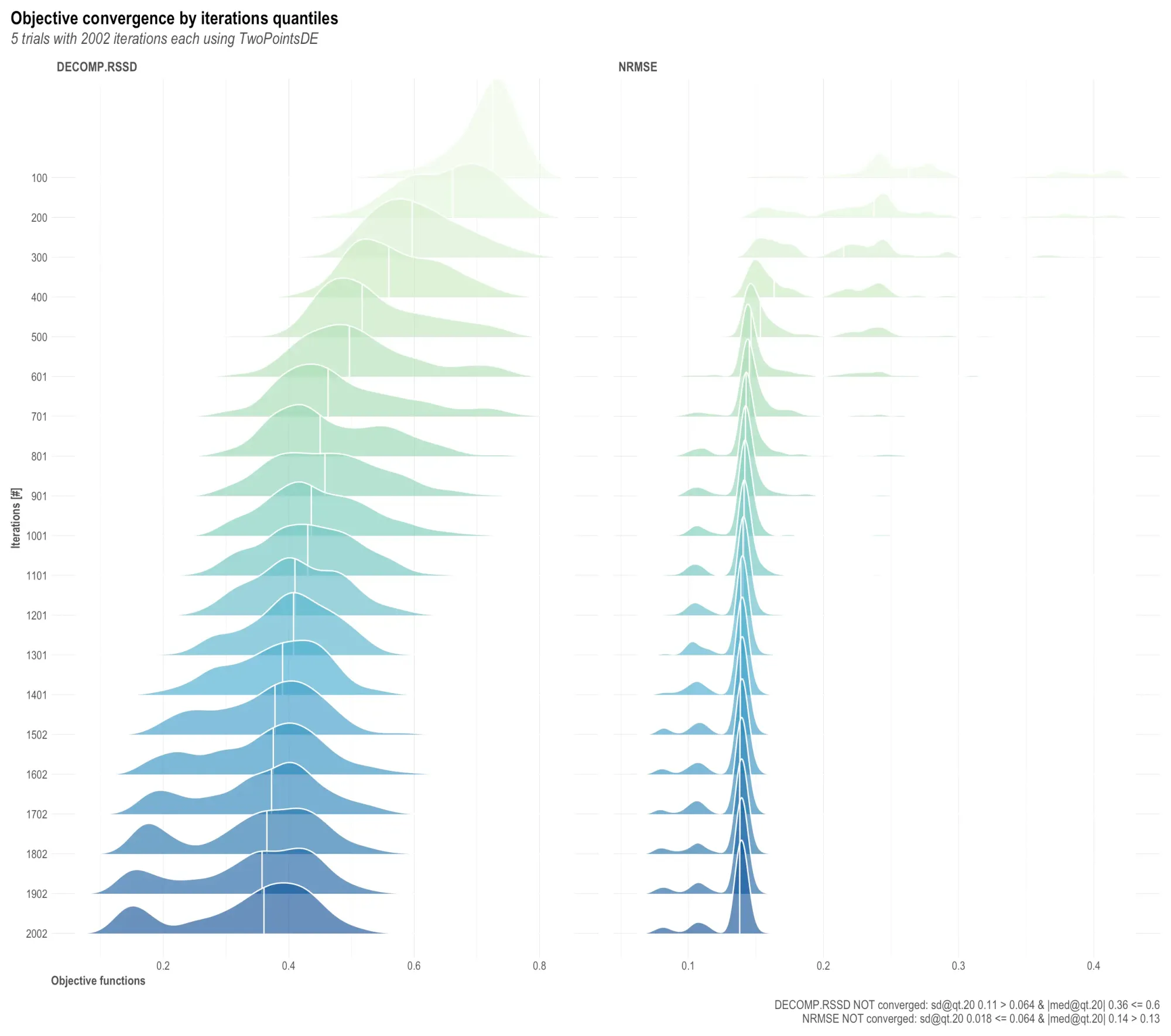
TwoPointDE 알고리즘으로 2002 번 이터레이션을 5 라운드 돌린 결과를 그래프로 그린 것입니다. y 축은 이터레이션 횟수로 아래쪽으로 갈수록 가장 나중의 이터레이션입니다. x 축은 목적 함수의 결과값이며 작을수록 학습이 잘 되어서 성능이 좋은 것으로 볼 수 있습니다.
이미지 우측 하단이 최종 결과인데요, 이 부분 해석이 중요합니다.
- DECOMP.RSSD 와 NRMSE 모두 NOT converged 로 결론이 났습니다. '수렴하지 않았다'는 것인데요, 이는 목표했던 낮은 값에는 도달하지 못했거나 균일하게 낮은 값을 보이지 못했다는 것으로 결국 '조금 더 학습을 해야 할 것 같다'로 해석할 수 있습니다.
- sd@qt.20 은 '이터레이션 내에서 20 백분위수(quantile)에 위치한 값들의 표준편차(standard deviation)'를 보겠다는 것을 의미합니다. 하위 20% 그룹에 위치한 값들이, 평균으로부터 떨어져있는 정도가 각 이터레이션에서 어떤 차이를 보이는지를 확인하는 것이 목적입니다.
- 표준편차가 작다면 이 모델이 비교적 안정적인 결과를 내고 있다고 볼 수 있고, 값이 크다면 그 반대로 해석하는 것이 맞을 것입니다.
- med@qt.20 은 표준편차가 아닌 중간값(median)을 사용합니다.
그래프 자체도 볼까요?
- DECOMP.RSSD는 이터레이션 횟수가 커질수록 그래프의 위치가 왼쪽으로 움직입니다. 즉 y가 커질수록 x가 작아집니다. x 값이 작을수록 학습이 잘 되는 것이므로, 반복 횟수가 많아질수록 결과가 좋아지는 경향이 보입니다.
- 그래프에서 가장 높이가 높은 부분이 최빈값입니다. 가장 많이 관찰된 값이죠.
- 그래프 오른쪽의 꼬리들이 이터레이션이 늘어날수록 줄어들고, 대신 그래프 앞쪽에 새로운 봉우리들이 생기는 것이 보입니다. 이터레이션을 늘리면 더 낮은 값으로 수렴하는 분포가 생길 수도 있겠다는 기대를 해볼만 한 부분인 것 같습니다.
아래 코드는 OutputModels 에 시계열 검증 데이터가 있다면 그것의 그래프를 불러오는 명령입니다. 실행해보죠.
if (OutputModels$ts_validation) OutputModels$ts_validation_plot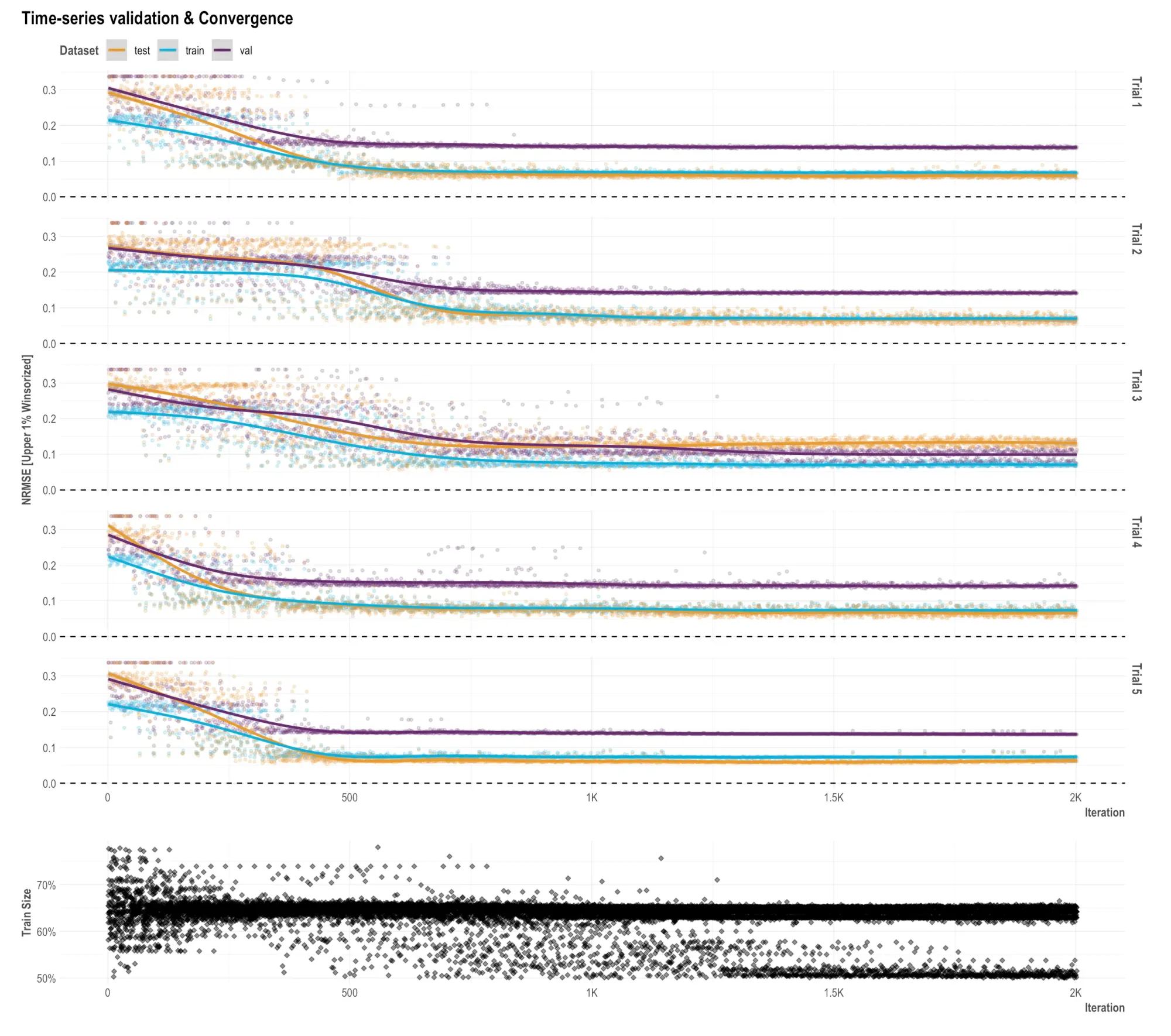
2000번 iterations를 5 라운드간 돌면서 각 데이터셋(train, validation, test)의 NRMSE 값이 어떻게 변하는지를 표현한 그래프입니다. 이렇게 볼 수 있을 것 같습니다.
- 이터레이션이 500회 정도 되는 시점에서 3 데이터셋 모두 NRMSE 최소값에 수렴하는 경향을 보입니다. 그래서 500회 이상 이터레이션을 가져가는게 큰 의미가 없을 수도 있겠다는 생각을 하게 됩니다.
- 전반적으로 train set과 test set은 수렴의 정도가 유사합니다. 일반화 성능이 잘 나오도록 학습이 잘 되었다고 볼 수 있습니다.
Calculate and Exports - 로빈의 결과물을 정리하고 분석
이제 마지막으로 최종 결과를 출력해보겠습니다. 아래 코드를 사용해주세요.
OutputCollect <- robyn_outputs(
InputCollect, OutputModels,
pareto_fronts = "auto", # automatically pick how many pareto-fronts to fill min_candidates (100)
# min_candidates = 100, # top pareto models for clustering. Default to 100
# calibration_constraint = 0.1, # range c(0.01, 0.1) & default at 0.1
csv_out = "pareto", # "pareto", "all", or NULL (for none)
clusters = TRUE, # Set to TRUE to cluster similar models by ROAS. See ?robyn_clusters
export = create_files, # this will create files locally
plot_folder = robyn_directory, # path for plots exports and files creation
plot_pareto = create_files # Set to FALSE to deactivate plotting and saving model one-pagers
)콘솔에 이런 메시지들이 올라옵니다. 모델의 결과를 평가하고 최적의 모델을 선택하는 단계를 밟는 것으로 이해하시면 됩니다.
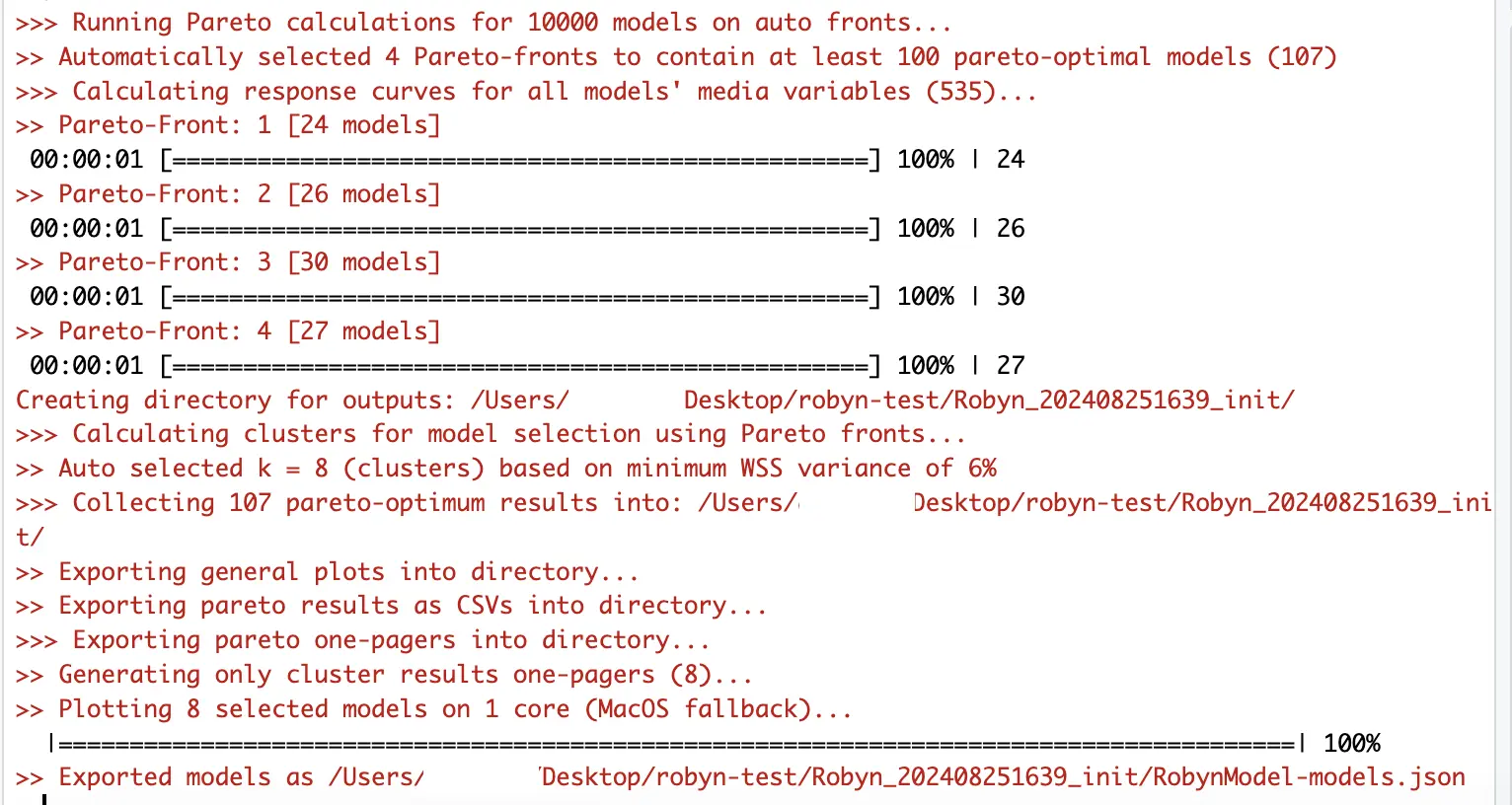
- 파레토 프론트 결정 - MMM으로 하려는 것은 1)ROI를 최대화 하면서, 동시에 2)spend를 최소화 하는 지점을 찾는 것입니다. 두 가지 목적에 최적화된 모델이 무엇인지 찾는 것을 '파레토 프론트를 결정한다'라고 이해하시면 좋습니다. 우리가 지금까지 한 것은 5 trial * 2000 iterations = 10,000개 모델을 만들고 결과를 평가하는 과정입니다. 이 만개 모델 중에서 최적을 찾아야 하는데, 이걸 사람이 하는게 아니라 로빈이 파레토 계산을 적용해서 최적 107개 모델 중 프론트 4개를 찾아주고 있는 것입니다.
- 이 모델들을 총 8개 군집으로 클러스터링 합니다. 유사한 특징을 가진 모델들을 묶어 놓으면, 나중에 그 안에서 최고의 모델을 찾기가 좋겠죠.
- 8개 모델에 대한 평가를 요약한 원페이저 8개를 만듭니다.
- 모델을 JSON 포맷으로 저장합니다.
이제 아래 명령을 실행해보죠.
print(OutputCollect)여러가지 숫자들이 출력될텐데요, 그게 모델 ID입니다. 마지막 Clusters (k = n): 이렇게 나오는 부분이 성능이 가장 좋은 모델들의 ID죠.
마치며 - 다음 단계
수고 많으셨습니다. 모델을 돌려보고 결과치까지 만들어 냈습니다. 다음에는 결과로 나온 원페이저를 보면서 해석을 해보겠습니다.
Comments ()