Meta MMM Robyn Walkthrough 03 - 로빈 모델 파라미터 세팅

지난 글에선 모델링할 데이터를 로빈에 로드하는 과정을 해봤습니다. 이번엔 모델이 이 데이터의 어떤 부분을 어떻게 다루면 될지를 결정하는 파라미터들을 세팅하는 과정을 진행합니다. 마찬가지로 Meta가 공식적으로 제공하는 demo.R 파일에 있는 튜토리얼 입니다.
Robyn - Step 2: 모델 상세설정 4단계
모델링을 돌려보려면 로빈에게 알려줘야 할 것들이 있습니다. 4번은 선택이기도 하고 공식 튜토리얼에선 건너뛰고 있으므로 이 글에서도 다루지 않습니다.
- 입력 변수 지정
- 하이퍼 파라미터 정의
- 데이터와 하이퍼 파라미터를 모델에 입력하기
- 선택 - 모델 교정(calibration)
Step 2-a1: 입력 변수 지정 (specify input variables)
로빈에 입력하려는 데이터가 어떤 속성을 가지는지를 모델에게 구체적으로 알려주는 단계입니다. 코드 상으로는 아래와 같이 되어있죠. 복사해서 콘솔에 붙여넣고 실행해 봅니다.
InputCollect <- robyn_inputs(
dt_input = dt_simulated_weekly,
dt_holidays = dt_prophet_holidays,
date_var = "DATE", # date format must be "2020-01-01"
dep_var = "revenue", # there should be only one dependent variable
dep_var_type = "revenue", # "revenue" (ROI) or "conversion" (CPA)
prophet_vars = c("trend", "season", "holiday"), # "trend","season", "weekday" & "holiday"
prophet_country = "DE", # input country code. Check: dt_prophet_holidays
context_vars = c("competitor_sales_B", "events"), # e.g. competitors, discount, unemployment etc
paid_media_spends = c("tv_S", "ooh_S", "print_S", "facebook_S", "search_S"), # mandatory input
paid_media_vars = c("tv_S", "ooh_S", "print_S", "facebook_I", "search_clicks_P"), # mandatory.
# paid_media_vars must have same order as paid_media_spends. Use media exposure metrics like
# impressions, GRP etc. If not applicable, use spend instead.
organic_vars = "newsletter", # marketing activity without media spend
# factor_vars = c("events"), # force variables in context_vars or organic_vars to be categorical
window_start = "2016-01-01",
window_end = "2018-12-31",
adstock = "geometric" # geometric, weibull_cdf or weibull_pdf.
)
print(InputCollect)코드를 보면 robyn_inputs() 함수에 여러가지 파라미터들이 들어가서 데이터가 되고, 이것을 InputCollect 객체에 넣는 과정입니다. 각 파라미터들의 역할은 다음과 같습니다.
| 주요 파라미터 | 설명 |
|---|---|
| dt_input | 모델에 입력하는 주 데이터로, 지난 글에서 로드했던 dt_simulated_weekly를 지정합니다. |
| dt_holidays | 시즈널리티를 반영하는데 필요한 휴일 데이터를 지정합니다. 이 예시에선 앞서 로드했던 dt_prophet_holidays 를 사용하고 있습니다. |
| date_var | 주 데이터 내에서 날짜 데이터를 가진 컬럼을 지정합니다. |
| dep_var | 이 종속 변수는 MMM이 측정할 주요 KPI이며 로드한 데이터에서 수익 또는 전환을 의미하는 데이터 중에서만 고를 수 있습니다. 이 예시에선 수익인 revenue 컬럼을 사용합니다. |
| dep_var_type | 위의 dep_var 에서 선택한 데이터의 유형이 revenue 인지 conversion 입력합니다. |
| prophet_vars | 이번 모델링에 Prophet의 네 변수들(추세, 계절성, 주중, 공휴일) 중 무엇을 고려할 것인지를 결정하는 부분입니다. |
| prophet_country | 위 prophet_vars 에서 선택한 데이터에서 특정 국가의 휴일만을 반영하려면 그 국가 코드를 입력합니다. 예시에서는 DE 를 사용하고 있습니다. 국가는 하나만 지정할 수 있습니다. |
| context_vars | 페이드 미디어 지출이 아니고 오가닉 활동도 아니지만 종속 변수(수익 또는 컨버전)에 영향을 줄 수 있는 변수가 있다면 여기에서 지정합니다. 이번 예시에서는 dt_simulated_weekly 파일에 있는 competitor_sales_B 와 events 데이터를 사용하고 있습니다. |
| paid_media_spends | 페이드 미디어에 지출한 비용 데이터를 매체 별로 입력합니다. 필수 파라미터이며, 즉 이 데이터가 있어야만 모델이 결과를 도출할 수 있습니다. |
| paid_media_vars | 위의 paid_media_spends 에 지출이 있다고 입력한 매체가 만들어낸 광고 지표를 여기에 입력합니다. 가장 좋은 것은 노출수, 클릭수, 광고 시청률입니다. 이 데이터가 없다면 위에 입력했던 비용 데이터를 그대로 다시 입력합니다. 역시 필수 파라미터 입니다. |
| organic_vars | 오가닉 마케팅 활동을 의미하는 데이터를 지정합니다. 이 예시에서는 newsletter 컬럼을 지정했죠. |
| factor_vars | 앞서 context_vars 에 몇가지를 입력했는데요, 여기에 들어간 데이터 중 연속형 데이터가 아닌 카테고리형 데이터가 있다면 이 factor_vars 에 그것을 지정해줘야 합니다. |
| window_start | 분석 시작 기간을 설정합니다. |
| window_end | 분석 종료 기간을 설정합니다. |
| adstock | 중요합니다. 광고의 효과가 나타나고 감소하는 것에는 '시간'이라는 요소도 변수로 작용합니다. 예를 들어 광고에 노출된 후 하루가 지나서 광고를 상기했다가, 그 다음날 구매하고, 일주일 후에는 완전히 광고를 잊는 경우가 있다는 것이죠. 이렇게 시간이 흐름에 따라 광고의 효과가 지연되고 이월되는 것을 어떤 함수로 계산할 것인지를 여기에서 지지정합니다. 이번 예시에는 geometric을 사용하고 있습니다. |
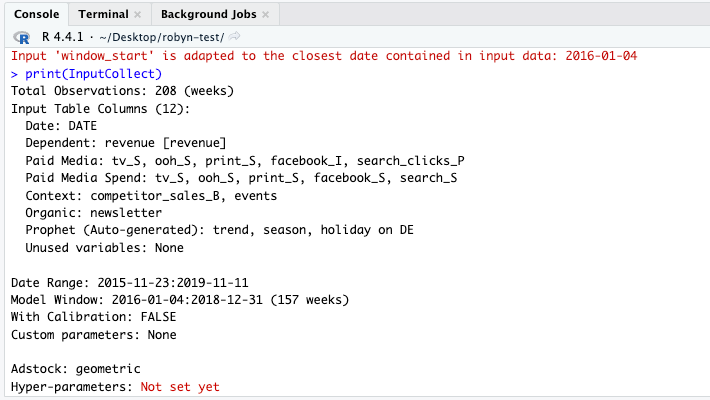
코드를 입력하고 나면 콘솔에 빨간색 글자가 표시됩니다.
> 'window_start' is adapted to the closest date contained in input data: 2016-01-04
코드에는 factor_vars 부분이 주석처리 되어있으나, 로빈이 데이터 유형을 자동으로 감지한 뒤 event 컬럼을 factor_vars 로 지정했습니다. 그리고 window_start 의 경우 코드 상으론 2016-01-01 로 되어있지만, 실제 데이터에는 이 날짜로된 데이터가 없어서 로빈이 자동으로 그 이후 날짜 중 가장 가까운 날짜인 2016-01-04 로 조정했습니다. 이렇게 자동으로 설정을 조정해주는 기능이 있어서 로빈을 사용하면서 실수를 줄이고 에러를 막는데 큰 도움이 된다고 생각합니다.
print(InputCollect) 의 결과로 아래와 같이 콘솔에 출력이 되었을 것입니다. InputCollect 객체가 어떤 데이터를 가지고 있는지 표시하게 되는데요, 가장 마지막 줄을 보면 Hyper-parameters: Not set yet 이렇게 되어있죠. 이제 하이퍼 파라미터를 세팅 해줘야 할 차례입니다.
Step 2-a2: 하이퍼 파라미터 정의
로빈은 머신 러닝을 활용하다보니 이쪽 분야 용어인 하이퍼 파라미터도 등장했습니다. 하이퍼 파라미터가 무엇인지를 이해하기 위해서는 파라미터와 하이퍼 파라미터가 어떻게 다른지를 보는 것이 가장 적절합니다.
- 파라미터 - 모델을 설정하는 사용자가 바꿀 수 없는 값들을 담게 되는 매개변수. 예를 들어 모델에 입력되는 데이터를 담고 있는 컬럼들이 여기에 해당됨.
- 하이퍼 파라미터 - 모델을 설정하는 사용자가 자의적으로 바꿀 수 있는 값들을 담게 되는 매개변수. 예를 들어 모델의 학습률, 데이터 배치 사이즈 등이 있으며, 이번 로빈 케이스에는 adstock 함수인 geometric 에서 사용할 세타값이 여기에 해당됨.
더 일상적인 예시로 스마트폰 볼륨을 생각해보죠. 음악을 재생하면 음원마다 기본 볼륨(게인)이 조금씩 다른 경우들이 있습니다. 그 음원 파일 자체에 설정되어 있는 기본 볼륨이 있고 이건 우리가 바꿀 수 없는데요, 이게 파라미터입니다. 그런데 우리는 스마트폰 단말기 자체의 볼륨을 바꿀 수가 있고, 이게 하이퍼 파라미터입니다.
로빈의 경우는 모델에 입력되는 데이터의 값을 우리가 임의로 바꿔서는 안되죠. 그러나 이 값을 이용해서 모델링된 결과를 만들어 내기 위한 가중치들은 목적에 따라서 바꿀 수 있습니다. 이렇게 우리가 바꿀 수 있는 것을 하이퍼 파라미터라고 보면 됩니다.
위에서 만든 InputCollect 객체는 아직 하이퍼 파라미터가 없습니다. 이걸 임의로 세팅해줘야 합니다. 데모에 있듯이 아래 코드를 복사해서 실행합니다.
hyper_names(adstock = InputCollect$adstock, all_media = InputCollect$all_media)hyper_names() 함수가 adstock 과 all_media 라는 파라미터를 받습니다. 이것의 결과로 모델이 사용해야 할 하이퍼 파라미터들의 명칭이 확정됩니다. 이런 결과가 나오죠.

InputCollect$adstock 은 geometric 입니다. 그래서 함수에 geometric이 입력 되었음을 알 수 있죠. 결과를 보면 all_media에 입력했던 비용 파라미터를 함수가 알파, 감마, 세타 세가지로 나눠 놓은 것이 보이네요. 이제 이 파라미터들에게 값을 설정해 줘야 합니다. 튜토리얼에서는 아래와 같은 값을 설정 하라고 권장 하는데요, 붙여넣고 실행해보죠.
hyperparameters <- list(
facebook_S_alphas = c(0.5, 3),
facebook_S_gammas = c(0.3, 1),
facebook_S_thetas = c(0, 0.3),
print_S_alphas = c(0.5, 3),
print_S_gammas = c(0.3, 1),
print_S_thetas = c(0.1, 0.4),
tv_S_alphas = c(0.5, 3),
tv_S_gammas = c(0.3, 1),
tv_S_thetas = c(0.3, 0.8),
search_S_alphas = c(0.5, 3),
search_S_gammas = c(0.3, 1),
search_S_thetas = c(0, 0.3),
ooh_S_alphas = c(0.5, 3),
ooh_S_gammas = c(0.3, 1),
ooh_S_thetas = c(0.1, 0.4),
newsletter_alphas = c(0.5, 3),
newsletter_gammas = c(0.3, 1),
newsletter_thetas = c(0.1, 0.4),
train_size = c(0.5, 0.8)
)각 하이퍼 파라미터의 용도는 이렇습니다.
- _thetas 접미사가 있는 파라미터: geometric adstock이 사용할 감소율 고정값 입니다. 예를 들어 위 코드에 tv_S_thetas = c(0.3, 0.8) 이렇게 되어있는데요, geometric 에선 0.3 ~ 0.8 사이의 값을 theta 로 사용하게 됩니다. 이 범위 안에서 무슨 값을 사용할지를 모델이 알아서 최적화합니다.
- _alphas, _gammas 접미사가 있는 파라미터 - 이 두 파라미터는 미디어 포화도(saturation)를 모델링하는데 사용됩니다. 포화도라는건 예산을 늘려도 성과가 더이상 좋아지지 않는 임계치라고 이해하시면 좋습니다. 이에 대한 자세한 설명은 여기를 참고해보세요. 알파와 감마를 조정했을때 그래프 모양이 어떻게 변하는지를 보면 더 빠르게 이해할 수 있습니다.
- train_size - 머신러닝 모델을 학습시켜 봤다면 익숙한 이름인데요, 주어진 데이터셋에서 어느정도 비율을 학습에 사용할지 결정하는 파라미터 입니다. 예를 들어0.7이라면 데이터의 70%는 모델에 학습시키고, 나머지 30% 중 절반인 15%는 모델 학습을 검증하는데 사용하고, 나머지 15%는 일반화 성능을 최종 테스트하는데 사용하게 됩니다.
이렇게 각 하이퍼 파라미터에 대해서 Meta가 기본값으로 세팅해놓은 값들은 경험적으로(rule-of-thumb) 결정되었다고 합니다. 조금 더 자세하게 알고 싶으신 경우 이 공식 문서를 참고해보세요.
Step 2-a3: 데이터와 하이퍼 파라미터를 모델에 입력하기
지금까지 설정한 내용들을 이제 모델에 넣어야 합니다. 아래 코드를 복사해서 콘솔에 입력합니다.
InputCollect <- robyn_inputs(InputCollect = InputCollect, hyperparameters = hyperparameters)모델이 자동으로 피처 엔지니어링을 진행합니다. 피처 엔지니어링은 입력된 데이터간의 상관관계를 확인하는 절차라고 이해하면 좋습니다. 예를 들어 최종적으로 예측해야 하는 것이 revenue 라면, 이 데이터와는 상관관계가 높은 데이터는 모델이 사용하고 그렇지 않은 데이터는 버릴 수 있습니다. 이렇게 하면 학습도 잘 되고 시간도 줄어드니까요.
맥북 사양이나 데이터 양에 따라서 피처 엔지니어링이 오래 걸릴 수도 있습니다. 이것이 끝나면 아래 코드를 입력해서 상태를 확인해 봅니다.
print(InputCollect)모델에 입력했던 결과가 InputCollect 객체에 들어와 있습니다. 입력된 데이터의 특성, 모델이 활용할 데이터 기간과 교정 여부, adstock에 사용할 펑션과 하이퍼 파라미터들이 보이죠.
Total Observations: 208 (weeks)
Input Table Columns (12):
Date: DATE
Dependent: revenue [revenue]
Paid Media: tv_S, ooh_S, print_S, facebook_I, search_clicks_P
Paid Media Spend: tv_S, ooh_S, print_S, facebook_S, search_S
Context: competitor_sales_B, events
Organic: newsletter
Prophet (Auto-generated): trend, season, holiday on DE
Unused variables: None
Date Range: 2015-11-23:2019-11-11
Model Window: 2016-01-04:2018-12-31 (157 weeks)
With Calibration: FALSE
Custom parameters: None
Adstock: geometric
Hyper-parameters ranges:
facebook_S_alphas: [0.5, 3]
facebook_S_gammas: [0.3, 1]
facebook_S_thetas: [0, 0.3]
print_S_alphas: [0.5, 3]
print_S_gammas: [0.3, 1]
print_S_thetas: [0.1, 0.4]
tv_S_alphas: [0.5, 3]
tv_S_gammas: [0.3, 1]
tv_S_thetas: [0.3, 0.8]
search_S_alphas: [0.5, 3]
search_S_gammas: [0.3, 1]
search_S_thetas: [0, 0.3]
ooh_S_alphas: [0.5, 3]
ooh_S_gammas: [0.3, 1]
ooh_S_thetas: [0.1, 0.4]
newsletter_alphas: [0.5, 3]
newsletter_gammas: [0.3, 1]
newsletter_thetas: [0.1, 0.4]
train_size: [0.5, 0.8]이 내용이 맞다면 이제 모델에 데이터를 넣고 결과를 뽑아볼 차례입니다.
마치며 - 다음 단계
모델 세팅까지 끝났습니다. 준비한 데이터와 설정을 모델에 넣고 실행시켜서 예측치를 뽑아볼 시간입니다. 다음 글에서 자세하게 다룹니다.
Comments ()